Hi 499ae,
Trong tương lai, tôi nghĩ sớm hay muộn, ngành du lịch sẽ ứng dụng AI Chatbot để phản hồi các hỏi đáp, yêu cầu của khách hàng. Hãy thử tưởng tượng, khách sạn của mình có một bạn AI ChatBot về F&B chuyên nhận order phòng giúp giảm tải cho các số hot line liên hệ đặt dịch vụ, hoặc một AI Income Auditor Bot có thể hỗ trợ phòng Kế Toán giảm tải các kiểm tra, đối chiếu liên quan từ dữ liệu đầu vào là các biểu mãu, báo cáo.... như vậy năng suất lao động có thể tăng lên đáng kể so với sức "CƠM".
Để làm được điều này, đầu tiên là các AI Chatbot này sẽ phải "hiểu được" câu chuyện nó đang trao đổi, trong đó "Ngôn Ngữ Lớn - Large Language Model - LLM) là thành phần chính không thể thiếu.
Vậy, LLM là gì? Nó hoạt động ra sao? Để tìm hiểu mô hình ngôn ngữ lớn là gì chúng ta sẽ điểm qua các nội dung từ bài viết:
Large language models, explained with a minimum of math and jargon
Khi ChatGPT được giới thiệu vào mùa thu năm ngoái, nó đã gây chấn động trong ngành công nghệ và cả thế giới. Trước đó, các nhà nghiên cứu học máy đã thử nghiệm với các mô hình ngôn ngữ lớn (LLMs) trong vài năm, nhưng công chúng chưa chú ý nhiều và không nhận ra sức mạnh của chúng.
Ngày nay, hầu như ai cũng đã nghe về LLMs, và hàng chục triệu người đã thử chúng. Tuy nhiên, không nhiều người thực sự hiểu cách chúng hoạt động.
Nếu bạn biết một chút về chủ đề này, có lẽ bạn đã nghe rằng LLMs được "huấn luyện để dự đoán từ tiếp theo" và cần một lượng lớn dữ liệu văn bản để làm điều này. Nhưng thường giải thích dừng lại ở đó, còn chi tiết về cách chúng dự đoán từ tiếp theo vẫn được coi là bí ẩn.
Nguyên nhân một phần là do cách phát triển hệ thống này rất khác thường. Phần mềm truyền thống được lập trình bởi con người với các hướng dẫn cụ thể, từng bước (if... then..else). Trong khi đó, ChatGPT được xây dựng trên mạng nơ-ron được huấn luyện với hàng tỷ từ ngôn ngữ thông thường.
Do đó, không ai trên thế giới thực sự hiểu hoàn toàn cơ chế bên trong của LLMs. Các nhà nghiên cứu vẫn đang cố gắng hiểu rõ hơn, nhưng đây là một quá trình chậm, có thể mất nhiều năm hoặc thậm chí nhiều thập kỷ.
Dù vậy, cũng có rất nhiều chuyên gia đã hiểu được nhiều điều về cách hoạt động của các hệ thống này. Mục tiêu của bài viết này là làm cho kiến thức đó trở nên dễ hiểu với đa số mọi người, tránh dùng thuật ngữ kỹ thuật hoặc toán học phức tạp.
Chúng tôi (tác giả bài báo, không phải là OP 😁)sẽ bắt đầu với việc giải thích về vector từ, cách thức đáng ngạc nhiên mà các mô hình ngôn ngữ này biểu diễn và suy luận về ngôn ngữ. Sau đó, chúng ta sẽ tìm hiểu sâu về transformer, nền tảng cơ bản cho các hệ thống như ChatGPT. Cuối cùng, chúng tôi sẽ giải thích cách các mô hình này được huấn luyện và tại sao hiệu suất tốt lại cần một lượng dữ liệu khổng lồ như vậy.
Để hiểu cách các mô hình ngôn ngữ hoạt động, trước tiên cần hiểu cách chúng đại diện cho từ ngữ. Con người biểu diễn từ ngữ bằng các chuỗi ký tự, như C-A-T cho CAT. Các mô hình ngôn ngữ sử dụng một danh sách dài các con số gọi là vector từ.
Ví dụ, đây là MỘT cách để biểu diễn từ CAT
[0.0045, -0.0023, 0.0098, -0.0342, 0.0156, …]
Xem đầy đủ từ biểu diễn 300 vector của CAT tại: Semantically related words for "cat_NOUN"
Tại sao lại sử dụng ký hiệu phức tạp như vậy? Đây là một ví dụ tương tự. Chẳng hạn, ta có các thành phố với tọa độ như sau:
Hà Nội nằm ở [21.0285, 105.8542]
TP.HCM nằm ở [10.8231, 106.6297]
Vientiane nằm ở [17.9757, 102.6331]
Phnom Penh nằm ở [11.5564, 104.9282]
Điều này hữu ích để lý giải về mối quan hệ không gian. Bạn có thể thấy TP.HCM gần Phnom Penh vì 10.8231 gần với 11.5564 và 106.6297 gần với 104.9282. Tương tự, Hà Nội gần với Vientiane hơn. Nhưng Hà Nội thì xa TP.HCM.
Các mô hình ngôn ngữ cũng áp dụng cách tiếp cận tương tự: mỗi vector từ đại diện cho một điểm trong "không gian từ" tưởng tượng, và những từ có ý nghĩa tương tự nhau được đặt gần nhau hơn. Từ này quá phức tạp để biểu diễn chỉ trong hai chiều, vì vậy các mô hình ngôn ngữ sử dụng không gian vector với hàng trăm hoặc thậm chí hàng nghìn chiều.
Ví dụ, những từ gần "Hà Nội" trong không gian vector có thể là "thủ đô", "Việt Nam", hoặc "đông dương". Điểm mạnh của cách biểu diễn này là khả năng thực hiện các phép tính toán học trên từ. Chẳng hạn, bạn có thể lấy vector của "Hà Nội", trừ đi "Việt Nam" và cộng "Campuchia", kết quả có thể gần với "Phnom Penh".
Khái niệm vector từ đã tồn tại từ lâu, nhưng trở nên phổ biến khi Google công bố dự án word2vec vào năm 2013. Google phân tích hàng triệu tài liệu để học cách các từ xuất hiện trong câu, sau đó sử dụng mạng nơ-ron để tạo ra các vector từ. Những từ có ý nghĩa tương tự (như "Hà Nội" và "Phnom Penh") được đặt gần nhau trong không gian vector. Mục đích là để xác định những từ nào thường xuất hiện trong các câu tương tự nhau.
Hơn nữa, vector từ còn cho phép "lý luận" thông qua toán học. Chẳng hạn, nếu lấy vector "lớn nhất" trừ "lớn" rồi cộng "nhỏ", kết quả gần nhất có thể là "nhỏ nhất".
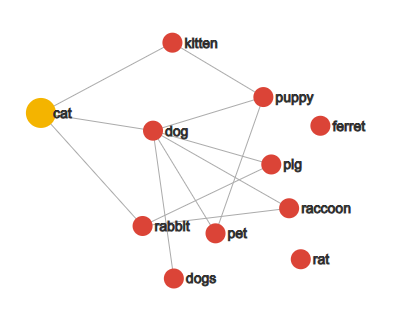
Quay lại với ví dụ CAT, ta có thể thấy mối liên hệ qua "không gian từ":
- "Mèo" và "chó" sẽ gần nhau vì chúng đều là thú cưng
- Từ càng xa trong ý nghĩa (ví dụ "rat" - chuột và "ferret" - chồn sương, "raccoon" - gấu mèo) thì càng ít có kết nối trực tiếp tới CAT.
Trong hình trên, chúng ta chỉ thấy được mối liên hệ đơn giản như "là thú cưng".
Nhưng thực tế, một từ như "mèo" có rất nhiều đặc điểm khác: có thể trèo cao, thích uống sữa, kêu "meo meo", săn chuột, có ria mép, thích ngủ, có 4 chân... và hàng trăm đặc điểm khác
Mỗi đặc điểm này sẽ cần một chiều riêng trong không gian vector để biểu diễn. Não người không thể tưởng tượng được không gian có nhiều chiều như vậy (chúng ta chỉ quen với 2-3 chiều), nhưng máy tính có thể dễ dàng xử lý và tạo ra các kết quả hữu ích từ những không gian nhiều chiều này. Hoặc:
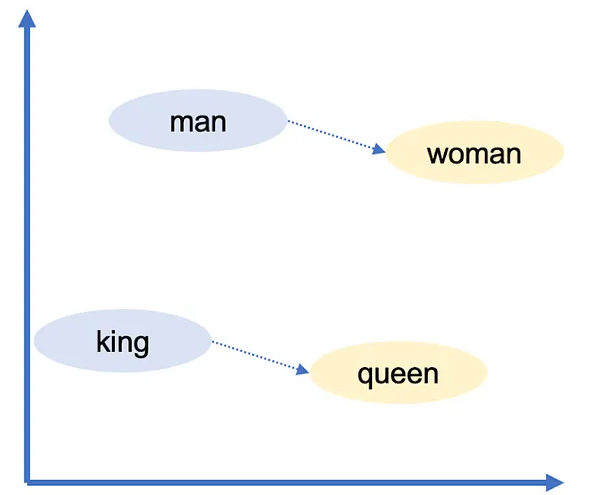
- vector("vua") - vector("đàn ông") + vector("phụ nữ") ~ vector("nữ hoàng")
Bởi vì các vector này được xây dựng từ cách con người sử dụng từ ngữ, chúng sẽ phản ánh nhiều định kiến hiện có trong ngôn ngữ của con người.
Ví dụ, trong một số mô hình vector từ, "bác sĩ" trừ "nam" cộng "nữ" sẽ cho ra kết quả là "y tá". Việc giảm thiểu những định kiến như thế này là một lĩnh vực đang được nghiên cứu tích cực. Đây được coi là định kiến vì nó phản ánh định kiến xã hội, ngầm định rằng bác sĩ thường là nam giới, và y tá thường là nữ giới. "Không gian từ" được tạo ra từ các phân tích hàng trăm triệu văn bản thực tế (OP), trong đó các văn bản này từ "bác sĩ" xuất hiện nhiều với đại từ "ông/anh", từ "y tá" thường xuất hiện với đại từ "cô/chị"- nên các mô hình học được mối liên hệ này từ dữ liệu có sẵn. Tuy nhiên, thực tế thì bác sĩ có thể là nam hoặc nữ, và y tá cũng có thể là nam hoặc nữ.
Tuy nhiên, vector từ vẫn là một khối xây dựng hữu ích cho các mô hình ngôn ngữ vì chúng mã hóa những thông tin tinh tế nhưng quan trọng về mối quan hệ giữa các từ. Nếu một mô hình ngôn ngữ học được điều gì đó về "mèo" (ví dụ: đôi khi phải đi khám thú y), điều tương tự cũng có thể đúng với "mèo con" hoặc "chó".
Nếu một mô hình học được mối quan hệ giữa "Hà Nội" và "Việt Nam" (ví dụ: họ nói cùng một ngôn ngữ), rất có thể điều tương tự cũng đúng với "Bangkok" và "Thái Lan" hoặc "Phnom Penh" và "Campuchia".
Điều này cho thấy các vector từ không chỉ nắm bắt ý nghĩa của từ mà còn cả những mối quan hệ và ngữ cảnh văn hóa-xã hội phức tạp trong cách chúng ta sử dụng ngôn ngữ.
 Jacobhax joined the community
Jacobhax joined the community MatthewPramb joined the community
MatthewPramb joined the community Coxxdilt joined the community
Coxxdilt joined the community Haroldjoina joined the community
Haroldjoina joined the community tmnmh joined the community
tmnmh joined the community Ronaldker joined the community
Ronaldker joined the community